

.net core導入千萬級數據至mysql數據庫的實現方法
最近在工作中,涉及到一個數據遷移功能,從一個txt文本文件導入到mysql功能。
數據遷移,在互聯網企業可以說經常碰到,而且涉及到千萬級、億級的數據量是很常見的。大數據量遷移,這里面就涉及到一個問題:高性能的插入數據。
今天我們就來談談mysql怎么高性能插入千萬級的數據。
我們一起對比以下幾種實現方法:
前期準備
訂單測試表
create table `trade` ( `id` varchar(50) null default null collate 'utf8_unicode_ci', `trade_no` varchar(50) null default null collate 'utf8_unicode_ci', unique index `id` (`id`), index `trade_no` (`trade_no`) ) comment='訂單' collate='utf8_unicode_ci' engine=innodb;
測試環境
操作系統:window 10 專業版
cpu:inter(r) core(tm) i7-8650u cpu @1.90ghz 2.11 ghz
內存:16g
mysql版本:5.7.26
實現方法:
1、單條數據插入
這是最普通的方式,通過循環一條一條的導入數據,這個方式的缺點很明顯就是每一次都需要連接一次數據庫。
實現代碼:
//開始時間
var starttime = datetime.now;
using (var conn = new mysqlconnection(connsql))
{
conn.open();
//插入10萬數據
for (var i = 0; i < 100000; i++)
{
//插入
var sql = string.format("insert into trade(id,trade_no) values('{0}','{1}');",
guid.newguid().tostring(), "trade_" + (i + 1)
);
var sqlcomm = new mysqlcommand();
sqlcomm.connection = conn;
sqlcomm.commandtext = sql;
sqlcomm.executenonquery();
sqlcomm.dispose();
}
conn.close();
}
//完成時間
var endtime = datetime.now;
//耗時
var spantime = endtime - starttime;
console.writeline("循環插入方式耗時:" + spantime.minutes + "分" + spantime.seconds + "秒" + spantime.milliseconds + "毫秒");
10萬條測試耗時:

上面的例子,我們是批量導入10萬條數據,需要連接10萬次數據庫。我們把sql語句改為1000條拼接為1條,這樣就能減少數據庫連接,實現代碼修改如下:
//開始時間
var starttime = datetime.now;
using (var conn = new mysqlconnection(connsql))
{
conn.open();
//插入10萬數據
var sql = new stringbuilder();
for (var i = 0; i < 100000; i++)
{
//插入
sql.appendformat("insert into trade(id,trade_no) values('{0}','{1}');",
guid.newguid().tostring(), "trade_" + (i + 1)
);
//合并插入
if (i % 1000 == 999)
{
var sqlcomm = new mysqlcommand();
sqlcomm.connection = conn;
sqlcomm.commandtext = sql.tostring();
sqlcomm.executenonquery();
sqlcomm.dispose();
sql.clear();
}
}
conn.close();
}
//完成時間
var endtime = datetime.now;
//耗時
var spantime = endtime - starttime;
console.writeline("循環插入方式耗時:" + spantime.minutes + "分" + spantime.seconds + "秒" + spantime.milliseconds + "毫秒");
10萬條測試耗時:

通過優化后,原本需要10萬次連接數據庫,只需連接100次。從最終運行效果看,由于數據庫是在同一臺服務器,不涉及網絡傳輸,性能提升不明顯。
2、合并數據插入
在mysql同樣也支持,通過合并數據來實現批量數據導入。實現代碼:
//開始時間
var starttime = datetime.now;
using (var conn = new mysqlconnection(connsql))
{
conn.open();
//插入10萬數據
var sql = new stringbuilder();
for (var i = 0; i < 100000; i++)
{
if (i % 1000 == 0)
{
sql.append("insert into trade(id,trade_no) values");
}
//拼接
sql.appendformat("('{0}','{1}'),", guid.newguid().tostring(), "trade_" + (i + 1));
//一次性插入1000條
if (i % 1000 == 999)
{
var sqlcomm = new mysqlcommand();
sqlcomm.connection = conn;
sqlcomm.commandtext = sql.tostring().trimend(',');
sqlcomm.executenonquery();
sqlcomm.dispose();
sql.clear();
}
}
conn.close();
}
//完成時間
var endtime = datetime.now;
//耗時
var spantime = endtime - starttime;
console.writeline("合并數據插入方式耗時:" + spantime.minutes + "分" + spantime.seconds + "秒" + spantime.milliseconds + "毫秒");
10萬條測試耗時:

通過這種方式插入操作明顯能夠提高程序的插入效率。雖然第一種方法通過優化后,同樣的可以減少數據庫連接次數,但第二種方法:合并后日志量(mysql的binlog和innodb的事務讓日志)減少了,降低日志刷盤的數據量和頻率,從而提高效率。同時也能減少sql語句解析的次數,減少網絡傳輸的io。
3、mysqlbulkloader插入
mysqlbulkloader也稱為load data infile,它的原理是從文件讀取數據。所以我們需要將我們的數據集保存到文件,然后再從文件里面讀取。
實現代碼:
//開始時間
var starttime = datetime.now;
using (var conn = new mysqlconnection(connsql))
{
conn.open();
var table = new datatable();
table.columns.add("id", typeof(string));
table.columns.add("trade_no", typeof(string));
//生成10萬數據
for (var i = 0; i < 100000; i++)
{
if (i % 500000 == 0)
{
table.rows.clear();
}
//記錄
var row = table.newrow();
row[0] = guid.newguid().tostring();
row[1] = "trade_" + (i + 1);
table.rows.add(row);
//50萬條一批次插入
if (i % 500000 != 499999 && i < (100000 - 1))
{
continue;
}
console.writeline("開始插入:" + i);
//數據轉換為csv格式
var tradecsv = datatabletocsv(table);
var tradefilepath = system.appdomain.currentdomain.basedirectory + "trade.csv";
file.writealltext(tradefilepath, tradecsv);
#region 保存至數據庫
var bulkcopy = new mysqlbulkloader(conn)
{
fieldterminator = ",",
fieldquotationcharacter = '"',
escapecharacter = '"',
lineterminator = "\r\n",
filename = tradefilepath,
numberoflinestoskip = 0,
tablename = "trade"
};
bulkcopy.columns.addrange(table.columns.cast<datacolumn>().select(colum => colum.columnname).tolist());
bulkcopy.load();
#endregion
}
conn.close();
}
//完成時間
var endtime = datetime.now;
//耗時
var spantime = endtime - starttime;
console.writeline("mysqlbulk方式耗時:" + spantime.minutes + "分" + spantime.seconds + "秒" + spantime.milliseconds + "毫秒");
10萬條測試耗時:

注意:mysql數據庫配置需開啟:允許文件導入。配置如下:
secure_file_priv=
性能測試對比
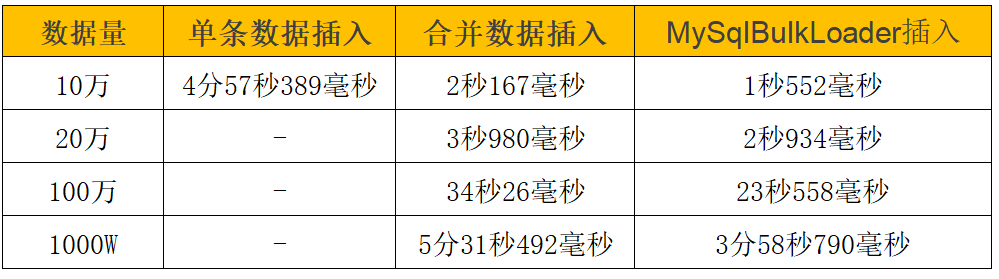
針對上面三種方法,分別測試10萬、20萬、100萬、1000萬條數據記錄,最終性能入如下:
最后
通過測試數據看,隨著數據量的增大,mysqlbulkloader的方式表現依舊良好,其他方式性能下降比較明顯。mysqlbulkloader的方式完全可以滿足我們的需求。
以上就是.net core導入千萬級數據至mysql數據庫的詳細內容,更多關于.net core導入千萬級數據至mysql的資料請關注碩編程其它相關文章!
 C++實戰
C++實戰