

python 系統(tǒng)和內(nèi)存架構(gòu)
在設(shè)計(jì)程序或并發(fā)系統(tǒng)時(shí),需要考慮不同的系統(tǒng)和內(nèi)存架構(gòu)樣式。這是非常必要的,因?yàn)橐粋€(gè)系統(tǒng)和內(nèi)存樣式可能適合于一個(gè)任務(wù),但可能容易出錯(cuò)其他任務(wù)。
支持并發(fā)的計(jì)算機(jī)系統(tǒng)體系結(jié)構(gòu)
michael flynn于1972年對(duì)分類不同風(fēng)格的計(jì)算機(jī)系統(tǒng)架構(gòu)進(jìn)行了分類。該分類法定義了以下四種不同的樣式
- 單指令流,單數(shù)據(jù)流(sisd)
- 單指令流,多數(shù)據(jù)流(simd)
- 多指令流,單數(shù)據(jù)流(misd)
- 多指令流,多數(shù)據(jù)流(mimd)。
單指令流,單數(shù)據(jù)流(sisd)
顧名思義,這種類型的系統(tǒng)將具有一個(gè)順序輸入數(shù)據(jù)流和一個(gè)單個(gè)處理單元來執(zhí)行數(shù)據(jù)流。它們就像具有并行計(jì)算架構(gòu)的單處理器系統(tǒng)。以下是sisd的架構(gòu)

sisd的優(yōu)點(diǎn)
sisd架構(gòu)的優(yōu)點(diǎn)如下 -
- 它需要更少的電力。
- 多核之間沒有復(fù)雜通信協(xié)議的問題。
sisd的缺點(diǎn)
sisd架構(gòu)的缺點(diǎn)如下 -
- sisd架構(gòu)的速度與單核處理器一樣有限。
- 它不適合大型應(yīng)用。
單指令流,多數(shù)據(jù)流(simd)
顧名思義,這種類型的系統(tǒng)將具有多個(gè)輸入數(shù)據(jù)流和多個(gè)處理單元,這些處理單元可以在任何給定時(shí)間作用于單個(gè)指令。它們就像具有并行計(jì)算架構(gòu)的多處理器系統(tǒng)。以下是simd的架構(gòu)
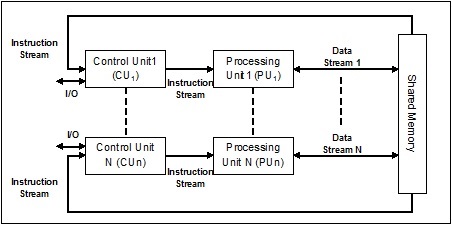
simd的最佳示例是顯卡。這些卡有數(shù)百個(gè)獨(dú)立的處理單元。如果我們談?wù)搒isd和simd之間的計(jì)算差異,那么對(duì)于添加數(shù)組 [ 5,15,20 ] 和 [ 15,25,10 ], sisd架構(gòu)必須執(zhí)行三種不同的添加操作。 另一方面,使用simd架構(gòu),我們可以在單個(gè)添加操作中添加。
simd的優(yōu)點(diǎn)
simd架構(gòu)的優(yōu)點(diǎn)如下
- 可以僅使用一個(gè)指令來執(zhí)行對(duì)多個(gè)元素的相同操作。
- 通過增加處理器的核心數(shù)量可以增加系統(tǒng)的吞吐量。
- 處理速度高于sisd架構(gòu)。
simd的缺點(diǎn)
simd架構(gòu)的缺點(diǎn)如下
- 處理器的核心數(shù)量之間存在復(fù)雜的通信。
- 成本高于sisd架構(gòu)。
多指令單數(shù)據(jù)(misd)流
具有misd流的系統(tǒng)具有多個(gè)處理單元,其通過在同一數(shù)據(jù)集上執(zhí)行不同的指令來執(zhí)行不同的操作。以下是misd的架構(gòu)
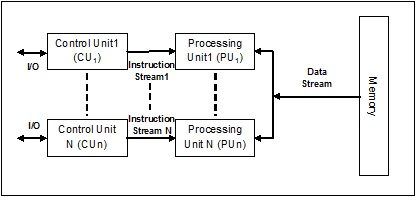
misd架構(gòu)的代表尚未商業(yè)化。
多指令多數(shù)據(jù)(mimd)流
在使用mimd架構(gòu)的系統(tǒng)中,多處理器系統(tǒng)中的每個(gè)處理器可以在不同的數(shù)據(jù)集并行上獨(dú)立地執(zhí)行不同的指令集。它與simd架構(gòu)相反,在simd架構(gòu)中,對(duì)多個(gè)數(shù)據(jù)集執(zhí)行單個(gè)操作。以下是mimd的架構(gòu)
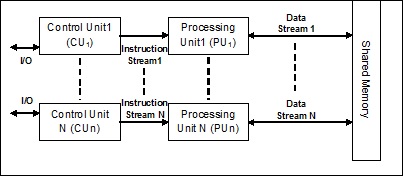
普通的多處理器使用mimd架構(gòu)。這些架構(gòu)主要用于許多應(yīng)用領(lǐng)域,如計(jì)算機(jī)輔助設(shè)計(jì)/計(jì)算機(jī)輔助制造,仿真,建模,通信開關(guān)等。
支持并發(fā)的內(nèi)存架構(gòu)
在使用并發(fā)和并行等概念的同時(shí),總是需要加速程序。計(jì)算機(jī)設(shè)計(jì)者發(fā)現(xiàn)的一個(gè)解決方案是創(chuàng)建共享存儲(chǔ)器多計(jì)算機(jī),即具有單個(gè)物理地址空間的計(jì)算機(jī),其由處理器所具有的所有核訪問。在這種情況下,可以有許多不同風(fēng)格的架構(gòu),但以下是三種重要的架構(gòu)風(fēng)格
uma(統(tǒng)一內(nèi)存訪問)
在此模型中,所有處理器均勻地共享物理內(nèi)存。所有處理器對(duì)所有存儲(chǔ)器字具有相同的訪問時(shí)間。每個(gè)處理器可以具有專用高速緩沖存儲(chǔ)器 外圍設(shè)備遵循一系列規(guī)則。
當(dāng)所有處理器對(duì)所有外圍設(shè)備具有相同的訪問權(quán)限時(shí),該系統(tǒng)稱為 對(duì)稱多處理器 。當(dāng)只有一個(gè)或幾個(gè)處理器可以訪問外圍設(shè)備時(shí),該系統(tǒng)稱為非對(duì)稱多處理器 。
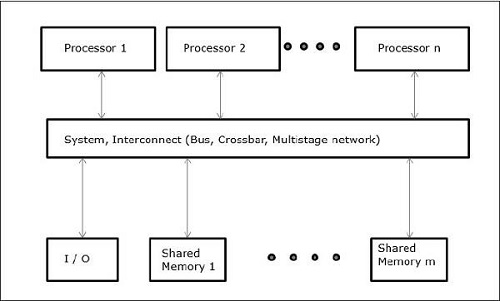
非均勻內(nèi)存訪問(numa)
在numa多處理器模型中,訪問時(shí)間隨存儲(chǔ)器字的位置而變化。這里,共享存儲(chǔ)器物理地分布在所有處理器中,稱為本地存儲(chǔ)器。所有本地存儲(chǔ)器的集合形成全局地址空間,可由所有處理器訪問。
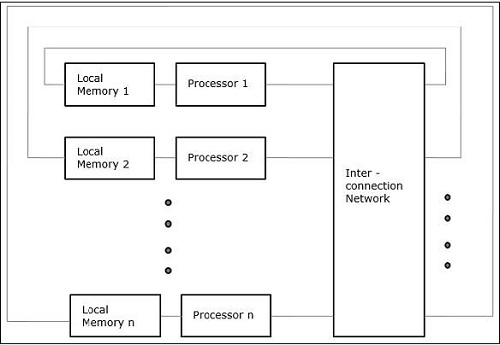
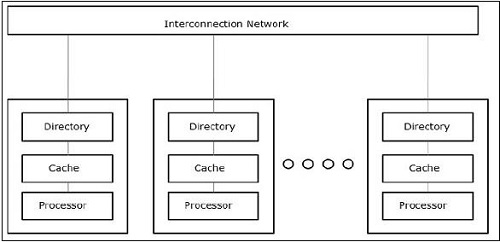
僅緩存內(nèi)存架構(gòu)(coma)
coma模型是numa模型的專用版本。這里,所有分布式主存儲(chǔ)器都被轉(zhuǎn)換為高速緩沖存儲(chǔ)器。
 Python技巧
Python技巧