

oracle常見分析函數實例詳解
1. 認識分析函數
1.1 什么是分析函數
分析函數是oracle專門用于解決復雜報表統計需求的功能強大的函數,它可以在數據中進行分組然后計算基于組的某種統計值,并且每一組的每一行都可以返回一個統計值。
1.2 分析函數和聚合函數的不同
普通的聚合函數用group by分組,每個分組返回一個統計值;而分析函數采用partition by 分組,并且每組每行都可以返回一個統計值。
1.3 分析函數的形式
分析函數帶有一個開窗函數over(),包含三個分析子句:分組(partition by),排序(order by), 窗口(rows),他們的使用形式如下:
over(partition by xxx order by yyy rows between zzz) -- 例如在scott.emp表中:xxx為deptno, yyy為sal, -- zzz為unbounded preceding and unbounded following
分析函數的例子:
顯示各部門員工的工資,并附帶顯示該部分的最高工資。
sql如下:
select deptno, empno, ename, sal, last_value(sal) over (partition by deptno order by sal rows between unbounded preceding and unbounded following) max_sal from emp;
結果為:
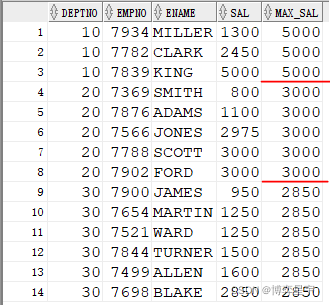
注: current row 表示當前行
unbounded preceding 表示第一行
unbounded following 表示最后一行
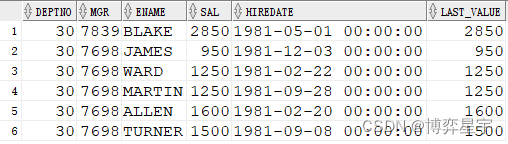
last_value(sal) 的結果與 order by sal 排序有關。如果排序為order by sal desc, 則最終的結果為分組排序后sal的最小值(分組排序后的最后一個值), 當deptno為10時,max_sal為1300。
2. 理解over()函數
2.1 兩個order by 的執行機制
分析函數是在整個sql查詢結束后(sql語句中的order by 的執行比較特殊)再進行的操作,也就是說sql語句中的order by也會影響分析函數的執行結果:
- 兩者一致:如果sql語句中的order by 滿足分析函數分析時要求的排序,那么sql語句中的排序將先執行,分析函數在分析時就不必再排序。
- 兩者不一致:如果sql語句中的order by 不滿足分析函數分析時要求的排序,那么sql語句中的排序將最后在分析函數分析結束后執行排序。
2.2 分析函數中的分組、排序、窗口
分析函數包含三個分析子句:分組(partition by)、排序(order by)、窗口(rows)。
窗口就是分析函數分析時要處理的數據范圍,就拿sum來說,它是sum窗口中的記錄而不是整個分組中的記錄。因此我們在想得到某個欄位的累計值時,我們需要把窗口指定到該分組中的第一行數據到當前行,如果你指定該窗口從該分組中的第一行到最后一行,那么該組中的每一個sum值都會一樣,即整個組的總和。
窗口子句中我們經常用到指定第一行,當前行,最后一行這樣的三個屬性:
- 第一行是 unbounded preceding
- 當前行是 current row
- 最后一行是 unbounded following
窗口子句不能單獨出現,必須有order by 子句時才能出現,如:
last_value(sal) over (partition by deptno order by sal rows between unbounded preceding and unbounded following )
以上示例指定窗口為整個分組.
而出現order by 子句的時候,不一定要有窗口子句,但效果會不一樣,此時窗口默認是當前組的第一行到當前行!
sql語句為:
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno order by sal) max_sal from emp;
等價于
select deptno, empno, ename, sal,last_value(sal) over(partition by deptno order by sal rows between unbounded preceding and current row) max_sal from emp;
結果如下圖所示:
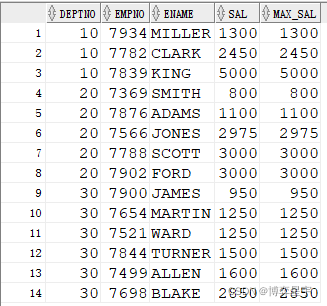
當省略窗口子句時:
- 如果存在order by, 則默認的窗口是 unbounded preceding and current row.
- 如果同時省略order by, 則默認的窗口是 unbounded preceding and unbounded following.
如果省略分組,則把全部記錄當成一個組:
- 如果存在order by 則默認窗口是unbounded preceding and current row
- 如果這時省略order by 則窗口默認為 unbounded preceding and unbounded following
2.3 幫助理解over()的實例
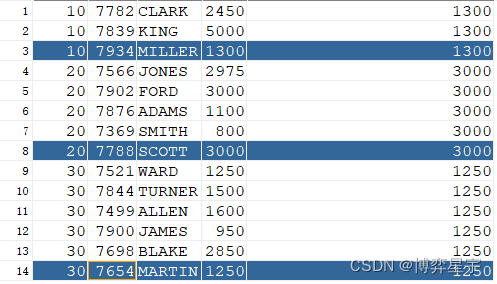
例1:關注點:sql無排序,over()排序子句省略
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno) from emp;
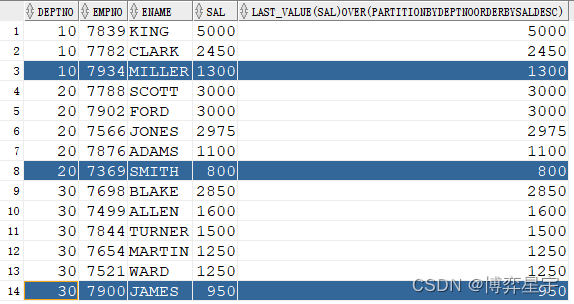
例2:關注點:sql無排序,over()排序子句有,窗口省略
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno order by sal desc) from emp;
例3:關注點:sql無排序,over()排序子句有,窗口也有,窗口特意強調全組數據
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno order by sal rows between unbounded preceding and unbounded following) max_sal from emp;
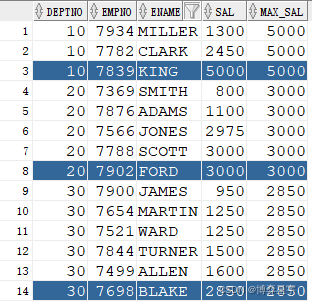
例4:關注點:sql有排序(正序),over() 排序子句無,先做sql排序再進行分析函數運算
select deptno, mgr, ename, sal, hiredate, last_value(sal) over(partition by deptno) last_value from emp where deptno=30 order by deptno, mgr;
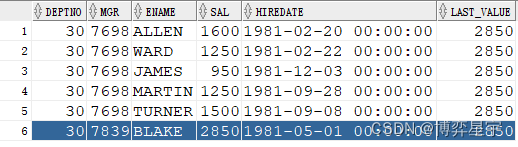
例5:關注點:sql有排序(倒序),over() 排序子句無,先做sql排序再進行分析函數運算
select deptno, mgr, ename, sal, hiredate, last_value(sal) over(partition by deptno) last_value from emp where deptno=30 order by deptno, mgr desc;
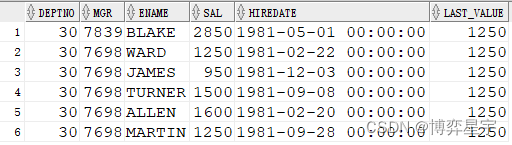
例6:關注點:sql有排序(倒序),over()排序子句有,窗口子句無,此時的運算是:sql先選數據但是不排序,而后排序子句先排序并進行分析函數處理(窗口默認為第一行到當前行),最后再進行sql排序
select deptno, mgr, ename, sal, hiredate, min(sal) over(partition by deptno order by sal)last_value from emp where deptno=30 order by deptno, mgr desc;
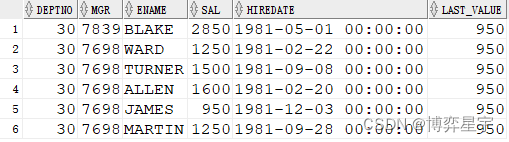
select deptno, mgr, ename, sal, hiredate, min(sal) over(partition by deptno order by sal desc) last_value from emp where deptno=30 order by deptno, mgr desc;
3. 常見分析函數
3.1 演示表和數據的生成
建表語句:
create table t( bill_month varchar2(12), area_code number, net_type varchar(2), local_fare number );
插入數據:
insert into t values('200405',5761,'g', 7393344.04);
insert into t values('200405',5761,'j', 5667089.85);
insert into t values('200405',5762,'g', 6315075.96);
insert into t values('200405',5762,'j', 6328716.15);
insert into t values('200405',5763,'g', 8861742.59);
insert into t values('200405',5763,'j', 7788036.32);
insert into t values('200405',5764,'g', 6028670.45);
insert into t values('200405',5764,'j', 6459121.49);
insert into t values('200405',5765,'g', 13156065.77);
insert into t values('200405',5765,'j', 11901671.70);
insert into t values('200406',5761,'g', 7614587.96);
insert into t values('200406',5761,'j', 5704343.05);
insert into t values('200406',5762,'g', 6556992.60);
insert into t values('200406',5762,'j', 6238068.05);
insert into t values('200406',5763,'g', 9130055.46);
insert into t values('200406',5763,'j', 7990460.25);
insert into t values('200406',5764,'g', 6387706.01);
insert into t values('200406',5764,'j', 6907481.66);
insert into t values('200406',5765,'g', 13562968.81);
insert into t values('200406',5765,'j', 12495492.50);
insert into t values('200407',5761,'g', 7987050.65);
insert into t values('200407',5761,'j', 5723215.28);
insert into t values('200407',5762,'g', 6833096.68);
insert into t values('200407',5762,'j', 6391201.44);
insert into t values('200407',5763,'g', 9410815.91);
insert into t values('200407',5763,'j', 8076677.41);
insert into t values('200407',5764,'g', 6456433.23);
insert into t values('200407',5764,'j', 6987660.53);
insert into t values('200407',5765,'g', 14000101.20);
insert into t values('200407',5765,'j', 12301780.20);
insert into t values('200408',5761,'g', 8085170.84);
insert into t values('200408',5761,'j', 6050611.37);
insert into t values('200408',5762,'g', 6854584.22);
insert into t values('200408',5762,'j', 6521884.50);
insert into t values('200408',5763,'g', 9468707.65);
insert into t values('200408',5763,'j', 8460049.43);
insert into t values('200408',5764,'g', 6587559.23);
insert into t values('200408',5764,'j', 7342135.86);
insert into t values('200408',5765,'g', 14450586.63);
insert into t values('200408',5765,'j', 12680052.38);
commit; 3.2 first_value()與last_value():求最值對應的其他屬性
問題:取出每個月通話費最高和最低的兩個地區
思路:先進行group by bill_month, area_code使用聚合函數sum()求解出by bill_month, area_code的local_fare總和, 即sum(local_fare),然后再運用分析函數進行求解每個月通話費用最高和最低的兩個地區。
select bill_month, area_code, sum(local_fare) local_fare, first_value(area_code) over(partition by bill_month order by sum(local_fare) desc rows between unbounded preceding and unbounded following) firstval, last_value(area_code) over(partition by bill_month order by sum(local_fare) desc rows between unbounded preceding and unbounded following) lastval from t group by bill_month, area_code;

3.3 rank()、dense_rank()與row_number() 排序問題
演示數據再oracle自帶的scott用戶下
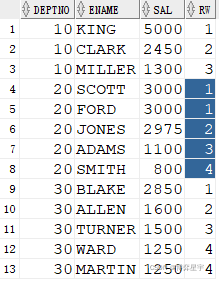
1.rank()值相同時排名相同,其后排名跳躍不連續
select * from ( select deptno, ename, sal, rank() over(partition by deptno order by sal desc) rw from emp ) where rw < 4;

2. dense_rank()值相同時排名相同,其后排名連續不跳躍
select * from ( select deptno, ename, sal, dense_rank() over(partition by deptno order by sal desc) rw from emp ) where rw <= 4;
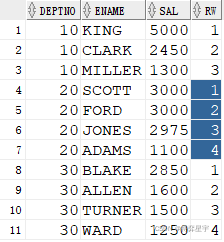
3. row_number()值相同時排名不相等,其后排名連續不跳躍
select * from ( select deptno, ename, sal, row_number() over(partition by deptno order by sal desc) rw from emp ) where rw <= 4;
3.4 lag()與lead():求之前或之后的第n行
lag(arg1, arg2, arg3):
- arg1:是從其他行返回的表達式
- arg2:是希望檢索的當前行分區的偏移量。是一個正的偏移量,是一個往回檢索以前的行數目
- arg3:是在arg2表示的數目超出了分組的范圍時返回的值
而lead()與lag()相反
select bill_month, area_code, local_fare cur_local_fare,
lag(local_fare, 1, 0) over(partition by area_code order by bill_month)
last_local_fare,
lead(local_fare, 1, 0) over(partition by area_code order by bill_month)
next_local_fare
from (select bill_month, area_code, sum(local_fare) local_fare
from t group by bill_month, area_code); 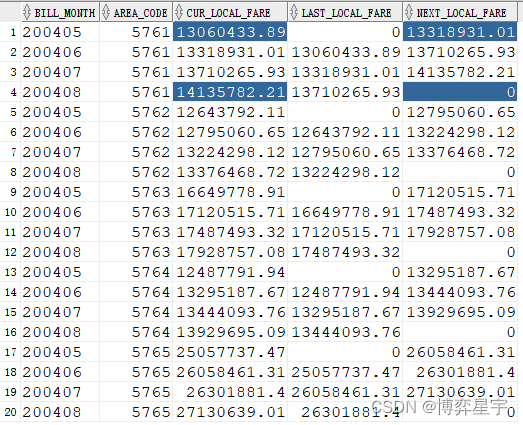
3.5 rollup()與cube():排列組合分組
group by rollup(a, b, c):
首先會對 (a, b, c) 進行group by,
然后再對 (a, b) 進行group by,
其后再對 (a) 進行group by,
最后對全表進行匯總操作。
group by cube(a, b, c):
則首先會對 (a, b, c) 進行group by,
然后依次是 (a, b), (a, c), (a), (b, c), (b), (c),
最后對全表進行匯總操作。
1.生成演示數據:
create table scott.tt as select * from dba_indexes;
2.普通group by 體驗
select owner, index_type, status, count(*) from tt where owner like 'sy%' group by owner, index_type, status;
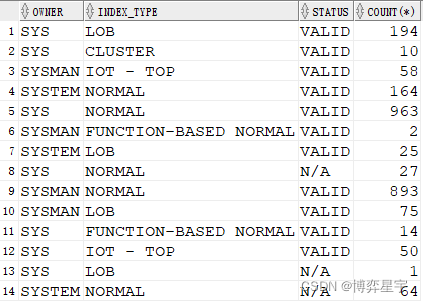
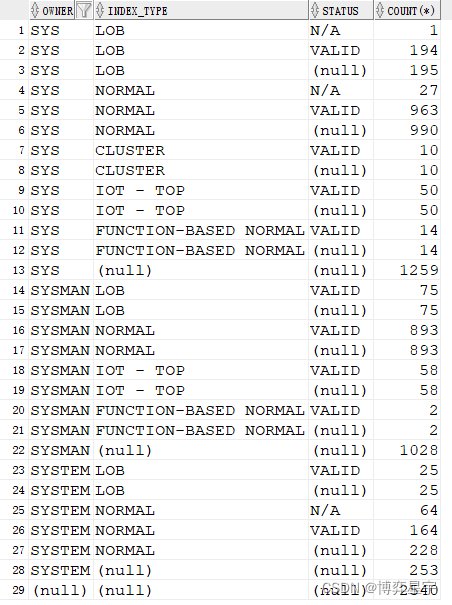
3. group by rollup(a, b, c):
首先會對 (a, b, c) 進行group by,
然后再對 (a, b) 進行group by,
其后再對 (a) 進行group by,
最后對全表進行匯總操作。
select owner, index_type, status, count(*) from tt where owner like 'sy%' group by rollup(owner, index_type, status);
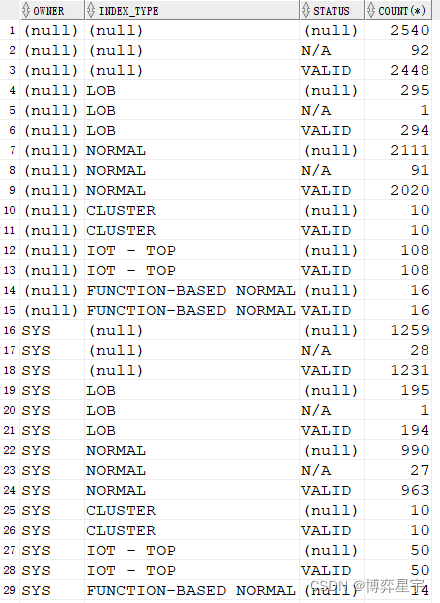
4. group by cube(a, b, c):
則首先會對 (a, b, c) 進行group by,
然后依次是 (a, b), (a, c), (a), (b, c), (b), (c),
最后對全表進行匯總操作。
select owner, index_type, status, count(*) from tt where owner like 'sy%' group by cube(owner, index_type, status);
(只截取了部分圖)
3.6 max()、min()、sum()與avg():求移動的最值、總和與平均值
問題:計算出各個地區連續3個月的通話費用的平均數(移動平均值)
select area_code, bill_month, local_fare,
sum(local_fare) over(partition by area_code order by to_number(bill_month)
range between 1 preceding and 1 following) month3_sum,
avg(local_fare) over(partition by area_code order by to_number(bill_month)
range between 1 preceding and 1 following) month3_avg,
max(local_fare) over(partition by area_code order by to_number(bill_month)
range between 1 preceding and 1 following) month3_max,
min(local_fare) over(partition by area_code order by to_number(bill_month)
range between 1 preceding and 1 following) month3_min
from (select bill_month, area_code, sum(local_fare) local_fare from t
group by area_code, bill_month); 
問題:求各地區按月份累加的通話費
select area_code, bill_month, local_fare, sum(local_fare) over(partition by area_code order by bill_month asc) last_sum_value from(select area_code, bill_month, sum(local_fare) local_fare from t group by area_code, bill_month) order by area_code, bill_month;

3.7 ratio_to_report():求百分比
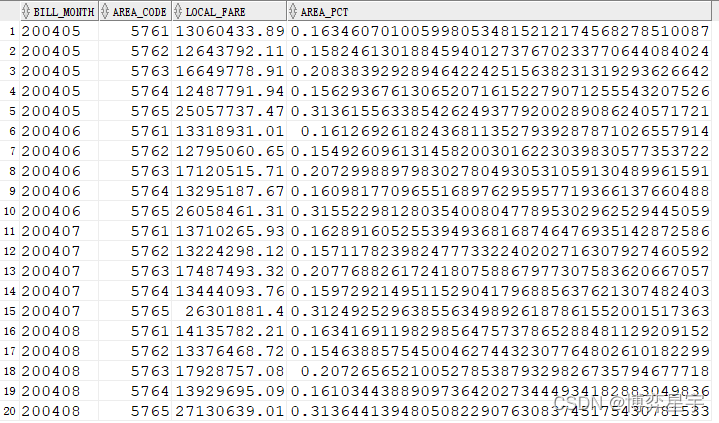
問題:求各地區花費占各月花費的比例
select bill_month, area_code, sum(local_fare) local_fare, ratio_to_report(sum(local_fare)) over (partition by bill_month) as area_pct from t group by bill_month, area_code;
總結
關于oracle常見分析函數的文章就介紹至此,更多相關oracle分析函數內容請搜索碩編程以前的文章,希望以后支持碩編程!
- Oracle 外鍵創建
- Oracle 級聯刪除外鍵
- Oracle Compose()函數
- Oracle Convert()函數
- Oracle Dump()函數
- Memcached 教程
- Memcached set 命令
- Memcached replace 命令
- Memcached incr 與 decr 命令
- Memcached stats 命令
- Memcached flush_all 命令
- PHP 連接 Memcached 服務
- DB2表
- DB2數據庫安全
- DB2 LDAP
- Oracle中的table()函數使用
- 關于ORA-04091異常的出現原因分析及解決方案
- 連接Oracle數據庫失敗(ORA-12514)故障排除全過程
- Oracle常見分析函數實例詳解
- Oracle報錯:ORA-28001:口令已失效解決辦法
 其他數據庫
其他數據庫